In today’s fast-paced digital landscape, the cost of performance degradation or downtime in applications can amount to millions of dollars for businesses. Integrating effective diagnostic capabilities into your applications is crucial for swiftly identifying and addressing issues. Let’s delve into the concept of distributed tracing and understand why it has become indispensable for ensuring system observability.
Distributed tracing, a relatively recent technique compared to traditional logging and application KPI metrics, is gaining prominence due to the escalating complexity of modern applications, particularly those built on middleware and microservices architectures. Imagine your application as a complex network of interconnected systems, similar to a cloud-native app illustrated by any kids sketch as below. Pinpointing bottlenecks within such intricate transactions involving numerous systems is a daunting task when relying solely on log data and conventional KPIs.
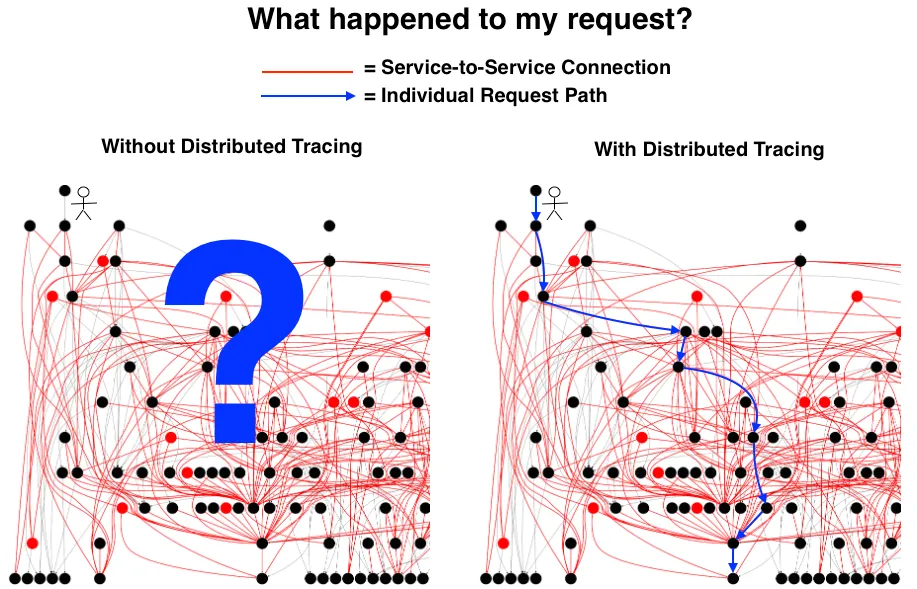
source: google
Distributed tracing addresses this challenge by meticulously capturing each discrete unit of work within an application and tracing its path through a distributed context. For instance, in a claims processing application, a distributed trace would document the journey of a single claim as it progresses through various tiers of microservices, whether executed locally or remotely, represented as trace spans. These spans, collectively forming a distributed trace, provide valuable insights into the sequence and timing of each step of a transaction as it traverses the system.
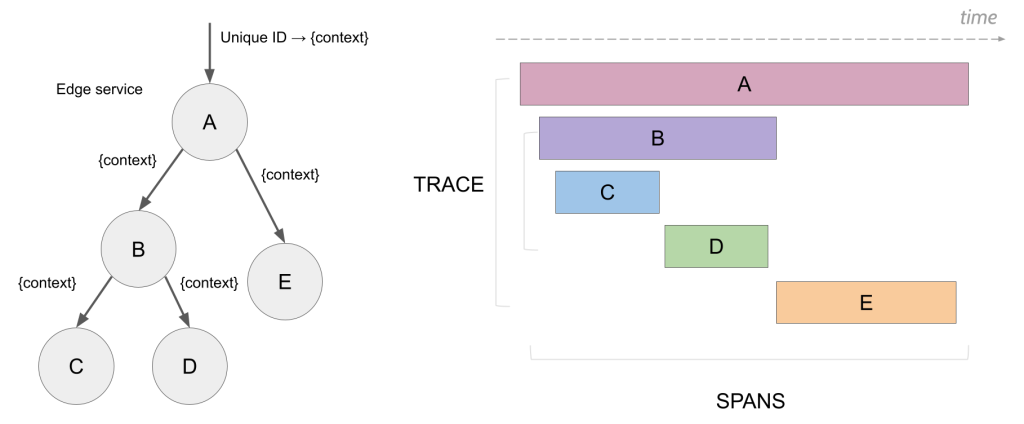
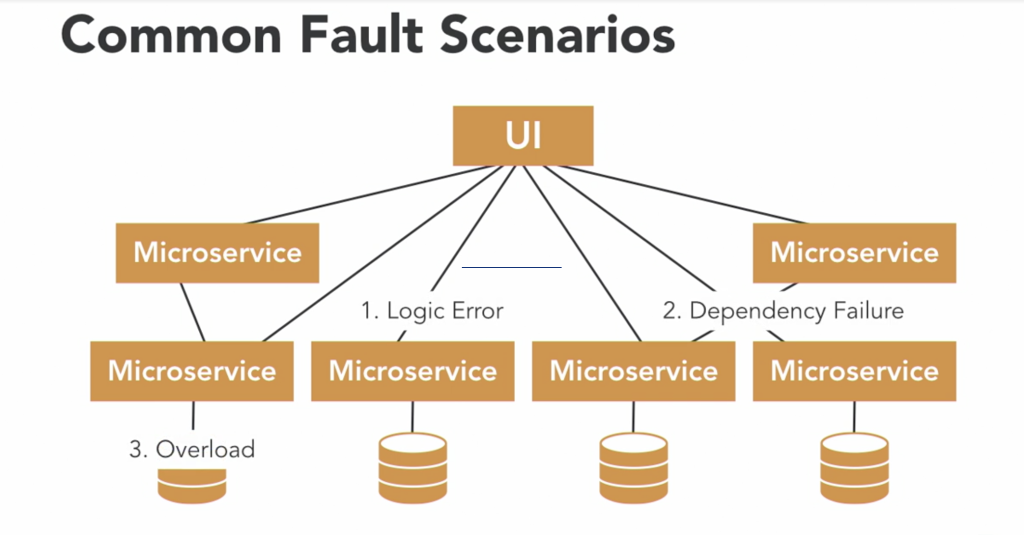
While the prospect of managing yet another tool may seem daunting, considering a few illustrative scenarios can underscore the value of distributed tracing. We can classify common problems into three categories:
- logic flaws
- dependency failures
- workload hotspots.
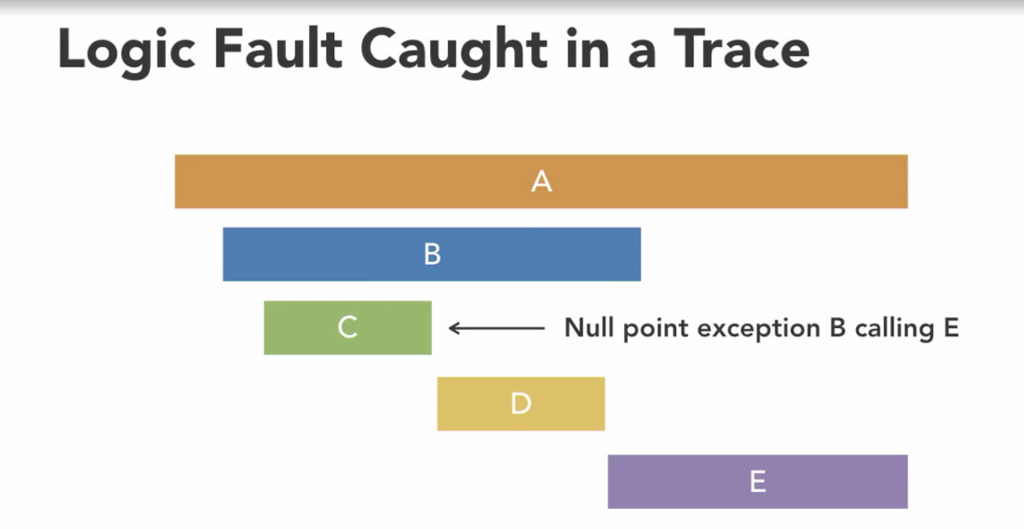
Logic flaws, such as untested scenarios leading to performance issues like null pointer exceptions, can be challenging to diagnose with traditional logging alone. Distributed tracing enables us to pinpoint the exact user action preceding the exception, facilitating quicker resolution.
Dependency failures, such as slow DNS lookups or malfunctioning microservice calls, pose significant challenges in distributed environments. With distributed tracing, identifying the specific tier or service causing the slowdown becomes more manageable, saving valuable time compared to combing through extensive logs.
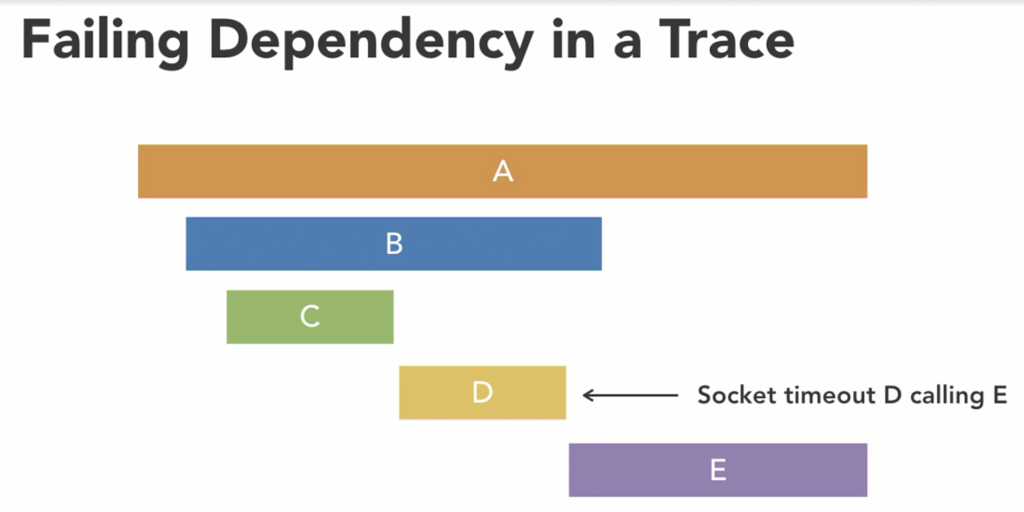
Workload hotspots, where sudden spikes in demand overwhelm system resources, further emphasize the necessity of distributed tracing. By providing contextual information on request propagation and downstream effects, distributed tracing aids in isolating the root cause of performance degradation, ensuring a more efficient resolution process.
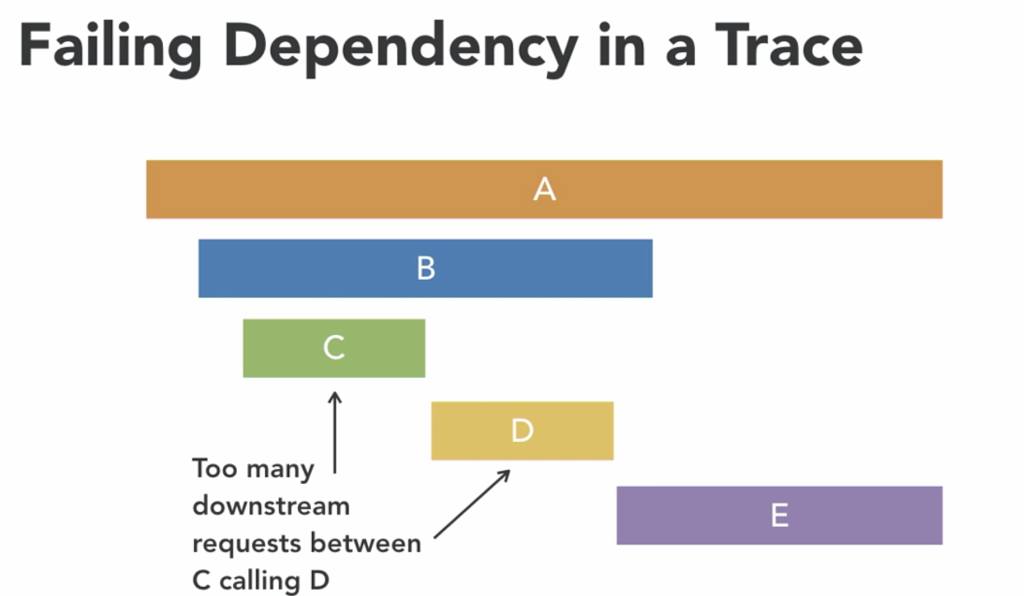
In conclusion, distributed tracing is not just another tool to manage; it is a crucial asset in diagnosing complex application issues and reducing mean time to resolution. Embracing distributed tracing is imperative for businesses seeking to maintain robust, high-performing applications in today’s dynamic digital landscape.